多様な歌唱スタイルに対応した楽曲検索システム
情報科学部
情報メディア学科
音声・音楽情報処理研究室
鈴木基之
教授
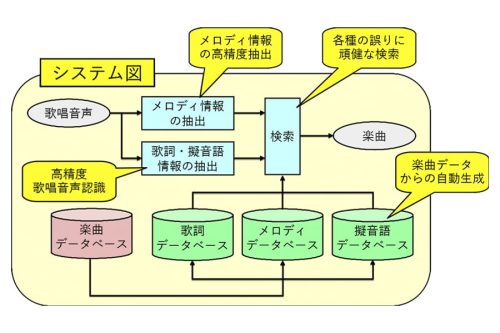
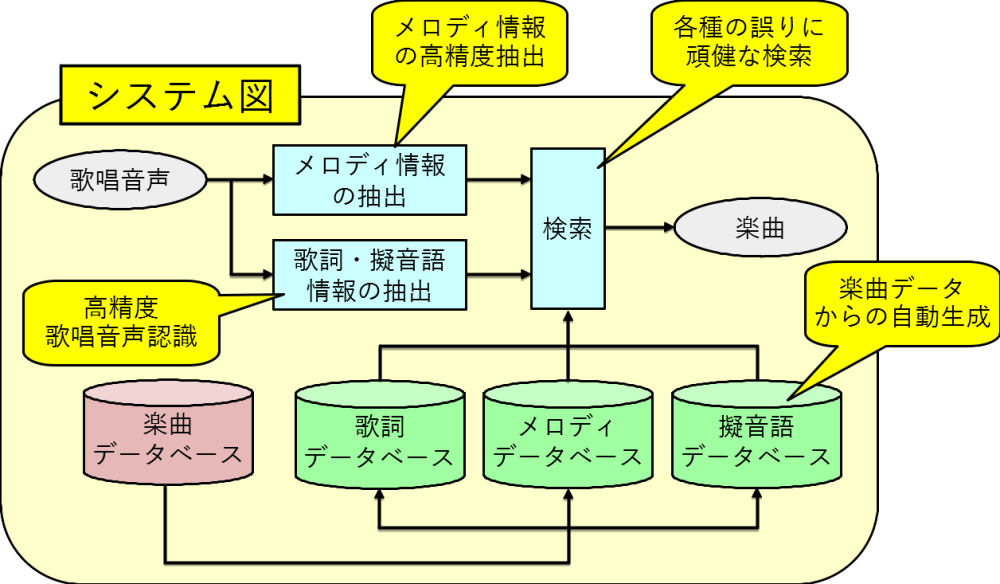
データベース中から楽曲を検索する際,題目や歌手名,といったメタ情報ではなく,楽曲を直接歌唱することで簡単に検索できるシステムを開発しています。
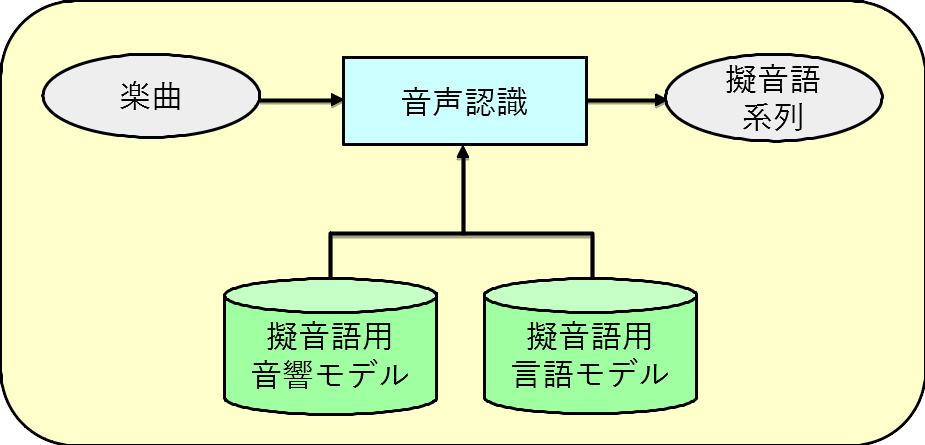
ハミング歌唱や歌詞による歌唱に加え,擬音語による歌唱にも対応し,またメロディの誤りや歌詞の誤りといった現象に対しても高精度に検索するための各種技術を開発しています。
論文
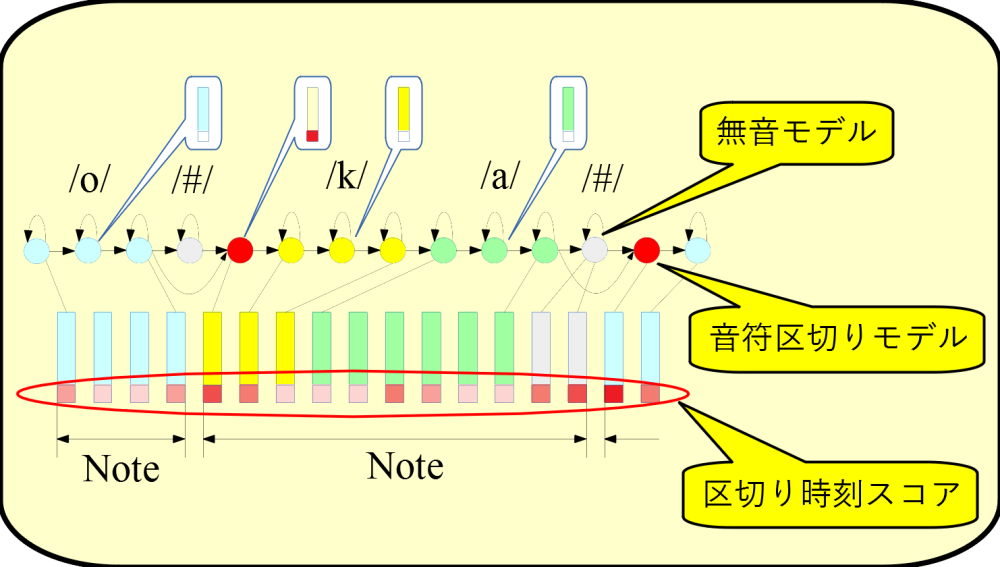
「音符区切り情報を用いた高精度歌唱音声認識」(2020)鈴木基之『情報処理学会論文誌』61(4)p.798-806.
「Lyrics recognition from singing voice focused on correspondence between voice and notes」(2019)SuzukiMotoyuki『Proc. INTERSPEECH 2019』p.3238-3241.
「Development of Singing-by-Onomatopoeia corpus for Query-by-Singing Music Information Retrieval system」(2017)SuzukiMotoyuki『International Journal of Advanced Intelligence』9(1)p.63-75.