微粒子クロマトグラフィー技術の実現に向けた次世代型マイクロ流体デバイス開発ユニット
プリンティング・エレクトロニクスにより作製した電極に誘電泳動現象を発現させることで微粒子を吸着する静電集塵用電極として応用。流路断面積が変化する高分子樹脂製マイクロ流体デバイスと組み合わせることで、流体のせん断力微粒子と静電気力を用いて微粒子を分離する。分離後、回収流路を用いてソーティングを実施することで微粒子を対象にしたクロマトクグラフィー技術としての実用化を目指す。
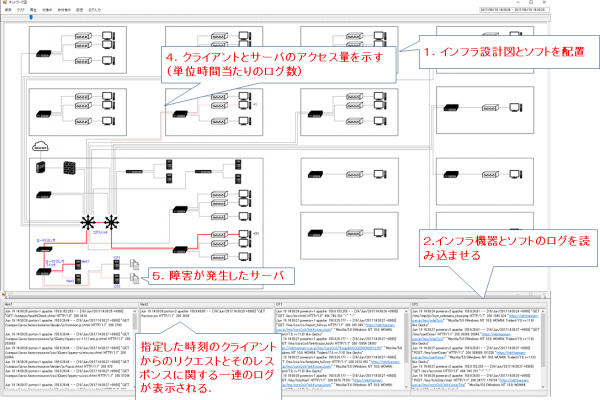
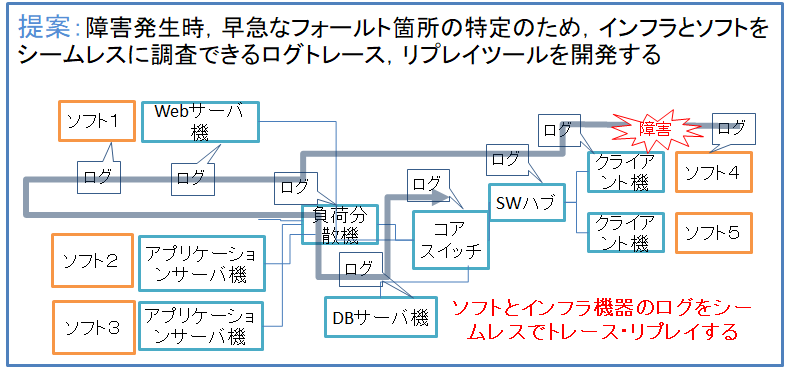
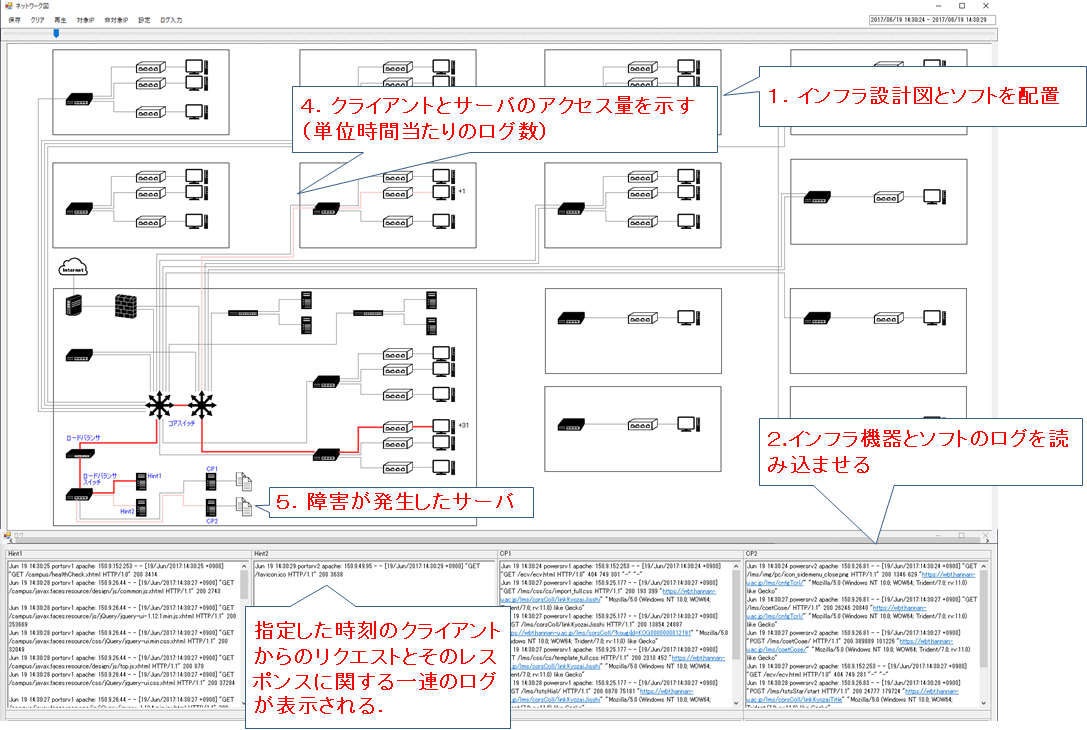
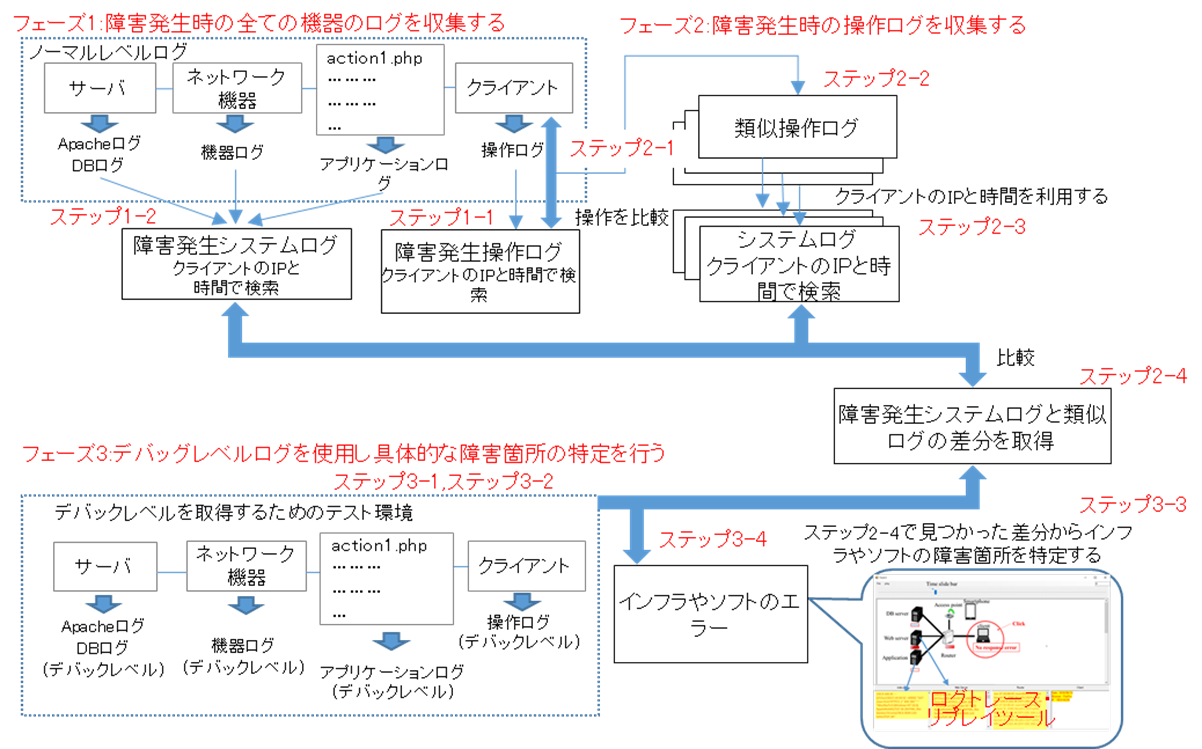
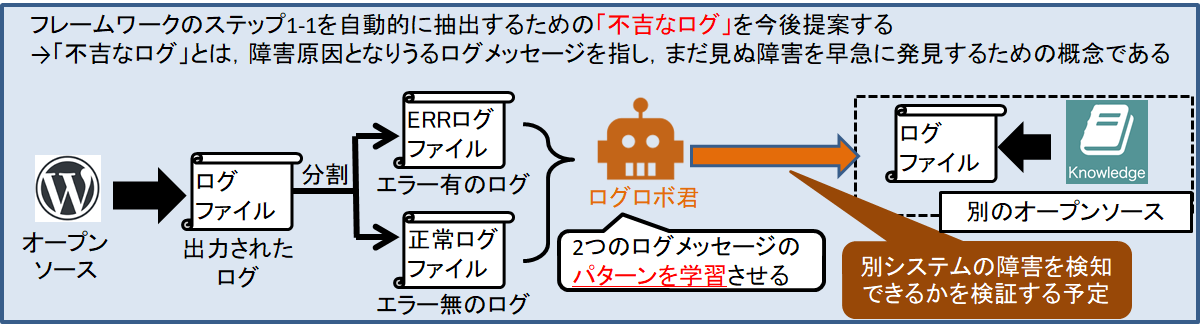
近年のシステムは様々なサーバ,ネットワーク機器,アプリケーション等のソフトウェアとインフラストラクチャ(インフラ),ままたはクラウドサービスが複雑さに関係しあうシステムが多い.このように複雑化する一方で,ソフトウェア,またはインフラ,クラウド等を環境に合わせて正常に設定する必要がある.しかし,設定項目が多すぎるため,設定ミスによる障害の発生や,更にどの機器に原因が発生したのかがわからない上に特定する事には多大なコストがかかる.複雑なシステムの障害を検出するための第1段階としてソフトとインフラをシームレスにリプレイするログリプレイヤのプロトタイプを開発した

研究シーズ・教員に対しての問合せや相談事項はこちら
技術相談申込フォーム© INNOVATION DAYS 2025 智と技術の見本市.