分極デバイス応用を目指した酸化ガリウム薄膜の研究
ワイドバンドギャップ半導体としてパワーデバイスや深紫外線検出器への応用が期待される酸化ガリウム薄膜に注目しています。特に準安定相構造の一つである ε 相の酸化ガリウムは自発分極による分極デバイスへの応用が期待されます。準安定相の成膜に適した手法であるミストCVD法を用いた高品質な薄膜の成膜とそのデバイス応用を検討しています。
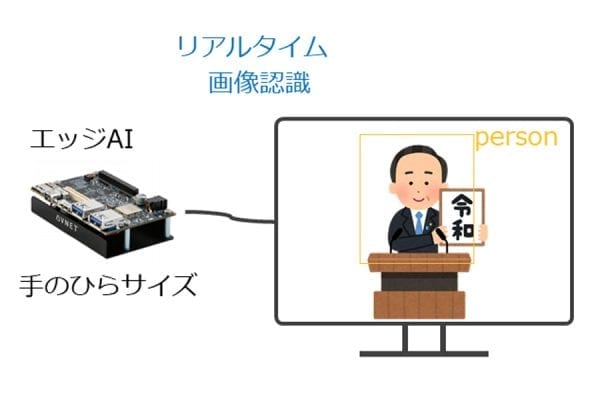
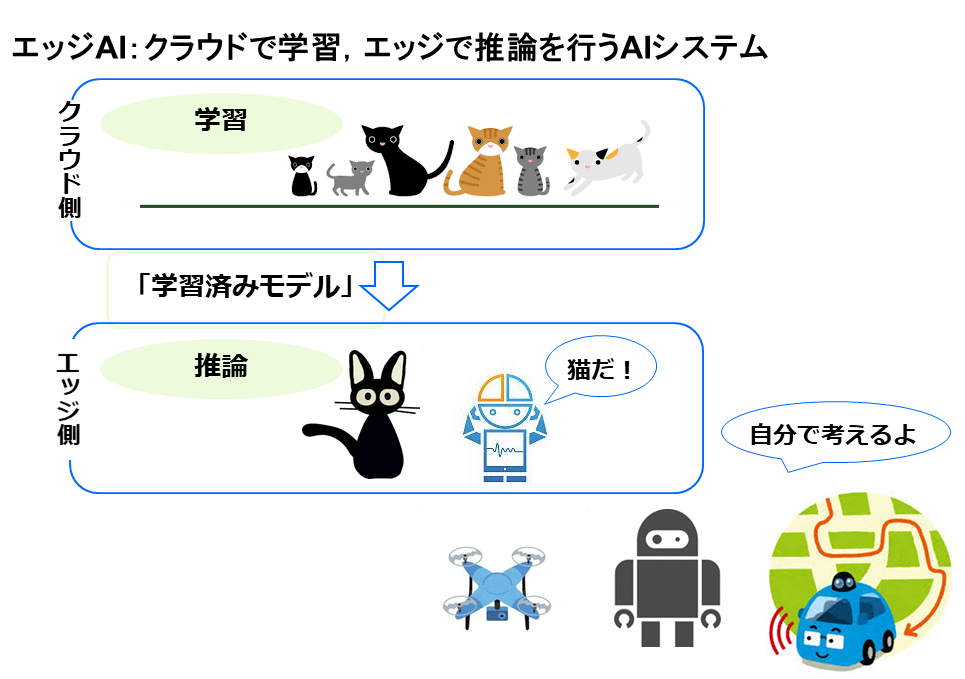
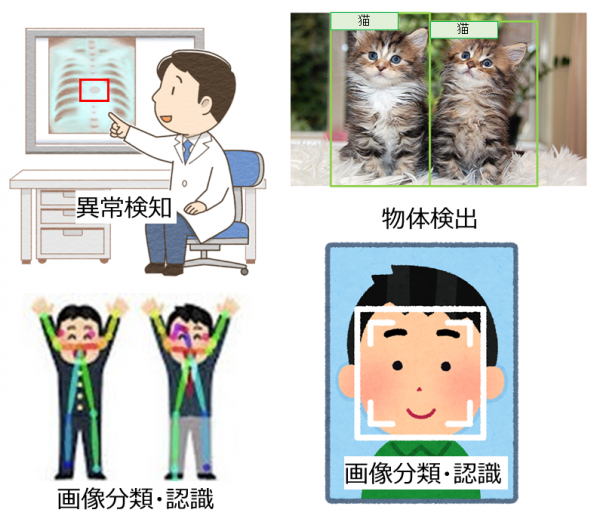
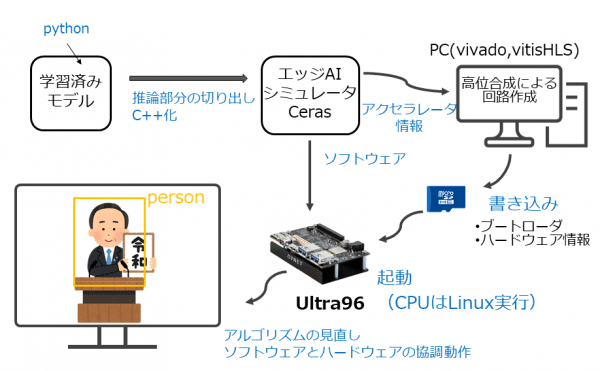
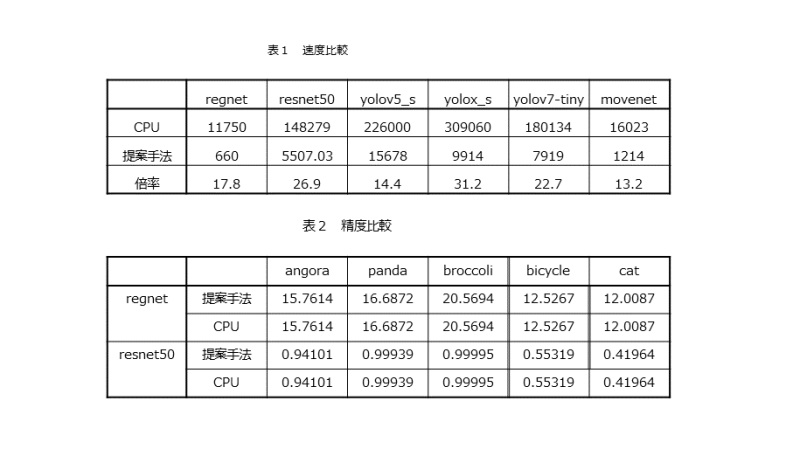
組み込み市場では,運用コストやセキュリティー,リアルタイム性などの問題から,エッジ(端末側)で単独処理できる「エッジAI」が期待されている.その実現方法であるFPGAによるエッジAIは根強いニーズがありながら,デバイスが高価格,実装が難しい,量子化による性能劣化という問題点があった.そこで,我々は,低価格のデバイスをターゲットにし,推論アルゴリズムを解析することで,効率よくアクセラレートする回路をFPGAで実装,処理を最適化することで,低消費電力で高速な推論処理を実現している.


研究シーズ・教員に対しての問合せや相談事項はこちら
技術相談申込フォーム© INNOVATION DAYS 2025 智と技術の見本市.